Contents
If you are unsure of the implementation, you can find the source code of my consistent hashing algorithm here.
What is Consistent Hashing?
Imagine we are running a large web service that serves millions of requests every hour. Now this web service serves the client by making HTTP requests to a backend, which in turn uses a database(s) to query data and return it to the client. Now, when you are using a web service, you will often return to the same page as you browse the web service, which means you will be making redundant calls to the database. This is a very performance-heavy operation since a database can have a lot of data, and filtering can take time. So how can we solve this? We need to use caches, which are in-memory data source(s) that store key-value pairs to store the request and the response. This way we won’t need to constantly call out to the database.
For a service this large, we would need quite a lot (and I mean a lot) of storage space. So, we would need several servers so the cumulative memory is sufficient. Well, now we arrive at a few more important questions…
If we have several server caches which store requests and responses:
-
Which server do we use to store the request?
-
Which server do we use to find the response given a request?
-
What if a cache server goes down? What happens to the data?
-
What if we add a server? How do we ease the load on the existing cache servers?
The optimal answer to all these questions lies in the implementation of consistent hashing.
Why is Consistent Hashing Important?
Short Answer: Because cache misses suck!
Long Answer: Let us look at a few latency metrics that impact our measurement:
| Operation Name | Time |
|---------------------------|-----------|
| L1 Cache Reference | 0.5ns |
| L2 Cache Reference | 7ns |
| Main Memory Reference | 100ns |
| Disk Seek | 10ms |
Now, with this table, we realize data missing from caches incurs a heavy performance penalty. The whole idea around consistency hashing is to minimize cache misses with the least amount of overhead. Additionally, it can be used to improve load distribution, enabling easier scaling of adding additional cache nodes.
How does consistent hashing work?
The brilliant idea behind consistency hashing is that no data is thrown away when nodes are removed. Additionally, a portion of the data is redistributed every time nodes are added.
I use nodes as a reference to cache servers
How is this possible? This is all possible through a structure called the
“Hash Ring” shown below:
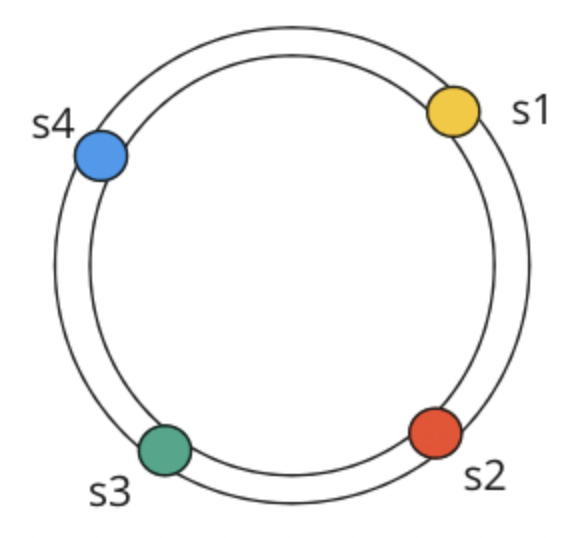
Nodes are distributed on a hash ring which allows us to efficiently determine which server stores what range of data. So, during, insertions we can split and redistribute the data and during deletions, we can replace the data. Specifically, the hash ring describes the range of keys that are stored and where we should store them. Suppose we get data with key $k=12$, we would travel clockwise from 12 until the first cache server we reach on the hash ring. That is where the data will be stored.
By way of example, in the diagram above we have 4 regions that are mapped, in a clockwise fashion to a specific server where the data will be stored.
The beautiful thing about a hash ring is that it can easily be built using an AVL tree, or in other words a self-balancing binary tree. This keeps the implementation extremely efficient as we do not have to go around a ring linearly trying to find a server to store the data.
class HashRing:
def __init__(self):
self.hashring = AVLTree()
We will be build out this class throughout this blog. Only upfront requirement is a AVL Tree.
Simple Hash Function
We will need to translate server identifiers to keys that are uniquely distributed.
During this implementation we will assume server identifiers are strings like
"s1" and we will translate them to integer keys through a simple hash function.
def hashInt(self, id):
hash = sha256(id.encode())
key = int(hash.hexdigest(), 16)
return key
Inserting a Node / Cache Server
To store data, we must first add a cache server or node to the hash ring. The first thing that we need to do is to translate the string key to the integer key. Now, we will add a node to the hash ring with the data as an empty AVL Tree. However, we will not keep it empty for long as that would be poor load distribution.
We want to redistribute the load on our successor since some of the keys don’t clockwise map on this node anymore. These keys along with their data need to be remapped to a new node. Thus, improving load distribution and reducing load contention.
Now during the remapping process, we need to be careful with one particular edgecase. Because of the nature of a ring-like structure, the smallest node with say id $s$ will need to store keys from $0…s$ but also keys that fall ahead of the largest node. I call these the loop over keys. And you may note later due to symmetry, the symmetrical operation of removing a node will also require handling such an edge case.
def putNode(self, nodeId):
# Get hashInt
key = self.hashInt(nodeId)
# Add the node to the AVLTree
# The data data stucture is also an AVLtree
self.hashring.insert(key, AVLTree())
node = self.hashring.find(key)
# Get the successor
successor = self.hashring.getSuccessorByNode(node)
# If no successor, the successor is the
# first node in the hashring
if successor is None:
successor = self.hashring.getSmallestNode()
# This is not the only added node
if successor.key != key:
# Move the data from successor which
# belongs to the current node
nodeDataTree = node.data
successorDataTree = successor.data
# The data that needs to move
# are the keys which fall before
# equal to the current keys value
nodesToMove = successorDataTree.getNodesWithSmallerKeys(key)
if self.hashring.isSmallestNode(key):
# Need to transfer the loop over keys
nodesToMove.extend(successorDataTree
.getNodesWithInvalidKeys(successor.key))
for node in nodesToMove:
nodeDataTree.insert(node.key, node.data)
successorDataTree.delete(node.key)
Removing a Node/Cache server
Removing a cache server or node has similar steps to adding a node. However, during deletion, we do not want to lose the data that was stored on that node because that would increase cache misses. We rather move the data to our successor as it is now responsible for holding the data.
You will again note that we are dealing with loop-around nodes since the nature of a ring-like structure requires integers to loop around once we reach the end. Therefore, these keys need to be handled with care as shown below:
def removeNode(self, nodeId):
# Get hashInt
key = self.hashInt(nodeId)
# Get the node
node = self.hashring.find(key)
# Get the successor
successor = self.hashring.getSuccessorByNode(node)
# Get smallest node incase
# If we later need to loop nodes around to the Start
smallestNode = self.hashring.getSmallestNode()
# If no successor, the successor is the
# first node in the hashring
if successor is None:
successor = self.hashring.getSmallestNode()
if successor is None:
print("All Nodes Cleared -- Dropping Remaining Data")
return
# We have not removed all servers
if successor.key != key:
# Move the data
nodeDataTree = node.data
successorDataTree = successor.data
smallestNodeDataTree = smallestNode.data
while not nodeDataTree.isEmpty():
dataKey, data = nodeDataTree.root.key, nodeDataTree.root.data
if dataKey > key:
# Loop around
smallestNodeDataTree.insert(dataKey, data)
else:
successorDataTree.insert(dataKey, data)
nodeDataTree.delete(nodeDataTree.root.key)
# delete node
self.hashring.delete(key)
With both insertion and deletion figured out, we can easily scale our caches without having to worry about minimizing cache misses. Data is maintained in the hashring as long as we have at least one node in the hashring at all times. Now all that is left to cover is how to add data to the hash ring, how to remove data from the hash ring and how to delete data from the hash ring.
Inserting Data
Now that we can add several nodes as potential caches, we need to cache the data. As mentioned before, inserting data is fairly easy, we need to move to the location where the data key belongs. Then find the first cache node we reach moving in a clockwise direction from that point forward.
def putData(self, id, data):
# Find the hashInt
key = self.hashInt(id)
# Find the node where data needs to go
successor = self.hashring.getSuccessorByKey(key)
if successor is None:
successor = self.hashring.getSmallestNode()
if successor is None:
print("No Storage Nodes")
return
# Add the data to the node
successorDataTree = successor.data
successorDataTree.insert(key, data)
Getting Data
Now that we can place data into that cache we need the ability to retrieve it. It follows that same process, hash the key, find the spot in the ring where the integer hash belongs, move clockwise until a node is reached. Boom. You can retrieve the data from that node guranteed. Assuming at some point you placed the data into the ring (of course).
def getData(self, id):
# Find hashInt
key = self.hashInt(id)
# Find the node where the data should exist
successor = self.hashring.getSuccessorByKey(key)
if successor is None:
successor = self.hashring.getSmallestNode()
if successor is None:
print("No Storage Node")
return
# Get the data from the node
successorDataTree = successor.data
return successorDataTree.find(key).data
Removing Data
Now that we can place the data and retrieve the data, we need a way to remove the data. Which, in all honesty, generally doesn’t happen in a cache since the data is removed when the cache becomes full through some protocol like LRU (Least-Recently-Used). However, we will implement a function to remove the data for completeness sake and testing purposes. Fortunately, removing data is not that much more complex and in fact, it is almost a similar process to the previous two. Hash the key into an integer find the integer on the ring, find the successor and then remove the data from that cache node.
def removeData(self, id):
# Get hashInt
key = self.hashInt(id)
# Find the node where data exists
successor = self.hashring.getSuccessorByKey(key)
if successor is None:
successor = self.hashring.getSmallestNode()
if successor is None:
print("No Storage Node")
return
# Remove the data from the node
successorDataTree = successor.data
successorDataTree.delete(key)
Final Thoughts
This algorithm is implemented in every distributed cache where it is vital to minimize cache misses and distribute load as equally as possible. With consistent hashing whenever we add a node we redistribute data from the successor reducing cache contention and whenever we remove a node we move the data to its successor which minimizes cache misses. There are more “add-ons” to this algorithm to further improve its performance, but these operations cover the critical implementation details and I encourage you to dive deeper if you are interested.